Um arquivo robots.txt é um arquivo de texto colocado na raiz do seu site de base de conhecimento que se comunica com rastreadores web e agentes automatizados. Ele especifica quais páginas ou seções do seu site os crawlers são permitidas ou não acessadas. Mecanismos de busca como Google, Bing e Yandex leem esse arquivo antes de rastrear seu site para determinar qual conteúdo devem indexar.
Um rastreador de teia, também conhecido como spider ou spiderbot, é um programa automatizado que navega pela web e coleta informações sobre sites. Crawlers abrem páginas, coletam dados como links, links quebrados, sitemaps e código HTML, e enviam para os servidores de seus mecanismos de busca para indexação.
No Document360, o arquivo robots.txt é acessível e pode ser editado diretamente pelas configurações do site da base de conhecimento. Isso se aplica a todo o seu site de base de conhecimento, não a artigos ou categorias individuais.
Quando usar Robots.txt
- Evite que os mecanismos de busca rastreiem e indexem seções internas, administrativas ou restritas da sua base de conhecimento.
- Bloqueie mecanismos de busca específicos de indexar completamente seu site, por exemplo, para controlar quais mecanismos de busca exibem seu conteúdo.
- Adicione regras de atraso de rastreamento quando seu site estiver enfrentando muito tráfego e você quiser reduzir a carga causada pela atividade dos bots.
- Combine robots.txt com seu sitemap para dar aos rastreadores um mapa claro do que indexar e o que pular.
Robots.txt controla o acesso do crawler no nível do site. Para excluir artigos ou categorias individuais dos resultados de busca, use as configurações de visibilidade de busca. Saiba mais sobre visibilidade em buscas
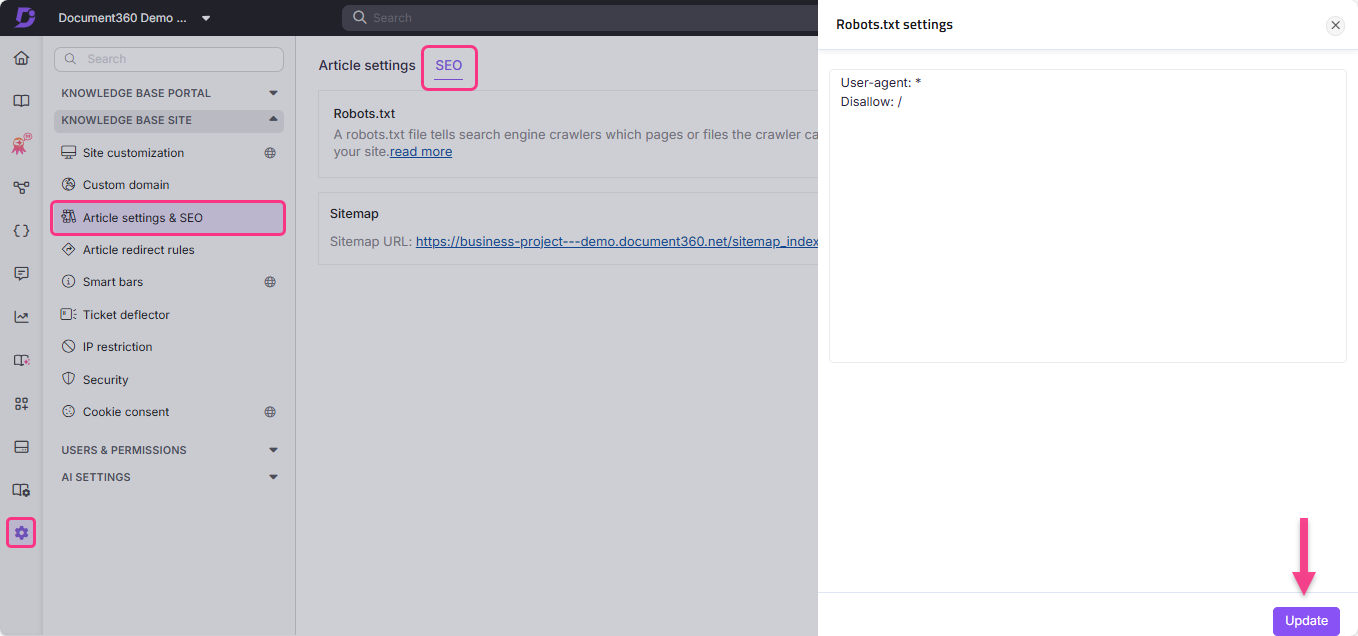
Acesse Robots.txt no Document360
- Navegue até Configurações () na barra de navegação da esquerda.
- Acesse o site da base de conhecimento > Configurações de artigos e SEO > aba SEO .
- Localize Robots.txt e clique em Editar. O painel de configurações Robots.txt aparece.
- Digite suas regras.
- Clique em Atualizar.
Regras Robots.txt comuns
Bloqueie todos os crawlers de um caminho específico
Use isso para impedir que rastreadores acessem dados de administrador ou seções restritas.
User-agent: *
Disallow: /admin/
Sitemap: https://example.com/sitemap.xml
User-agent: *Aplica a regra a todos os crawlers.Disallow: /admin/impede que rastreadores acessem o caminho de administrador.Sitemap:fornece a URL do sitemap para que os rastreadores possam descobrir todas as páginas indexadas de forma eficiente.
Bloqueie um mecanismo de busca específico
Use isso para evitar que um determinado mecanismo de busca rastreie seu site.
User-agent: Bingbot
Disallow: /
User-agent: Bingbotmira apenas o rastreador do motor de busca do Bing.Disallow: /impede que o Bingbot rastreie qualquer página do site.
Adicionar um atraso de rastreamento
Use isso para desacelerar a velocidade de rastreamento dos bots quando seu site está sob alta carga de tráfego.
User-agent: *
Crawl-delay: 10
Crawl-delay: 10instrui os rastreadores a aguardarem 10 segundos entre as solicitações.
Melhores práticas
- Sempre inclua a URL do seu sitemap no arquivo robots.txt para que os rastreadores possam facilmente descobrir suas páginas indexadas.
- Bloqueie páginas que não oferecem valor para os usuários dos mecanismos de busca, como caminhos de administrador, páginas de login ou caminhos de conteúdo duplicados.
- Não use robots.txt como medida de segurança. É um arquivo público e não impede o acesso humano não autorizado. Use as configurações de controle de acesso para isso.
- Evite bloquear arquivos CSS ou JavaScript que os mecanismos de busca precisam renderizar e entender suas páginas.
- Siga as diretrizes de formato do Google Search Central para garantir que seu arquivo seja válido.
- Teste suas regras de robots.txt usando o testador de robots.txt do Google Search Console antes de implantar as mudanças.
FAQ
Qual é a diferença entre as configurações de visibilidade Robots.txt e de busca no Document360?
Robots.txt se aplica ao nível do site e controla quais caminhos ou seções os rastreadores podem acessar em toda a sua base de conhecimento. As configurações de visibilidade de busca se aplicam no nível do artigo ou categoria e permitem excluir conteúdos específicos de mecanismos de busca externos, da barra de busca da base de conhecimento ou da busca assistiva Eddy AI de forma independente. Use ambos juntos para controle preciso sobre o que é indexado.
Como faço para remover meu projeto Document360 do índice de busca do Google?
Vá em Configurações () > site da base de conhecimento > Configurações de artigos e SEO > aba SEO , clique em Editar em Robots.txt, cole o código a seguir e clique em Atualizar.
User-Agent: Googlebot
Disallow: /
Como faço para evitar que páginas de tag sejam indexadas pelos mecanismos de busca?
Vá em Configurações () > site da base de conhecimento > Configurações de artigos e SEO > aba SEO , clique em Editar em Robots.txt, cole o código a seguir e clique em Atualizar.
User-agent: *
Disallow: /docs/en/tags/
A Robots.txt impede que todos os rastreadores acessem páginas bloqueadas?
Robots.txt é um padrão voluntário. A maioria dos buscadores de motores de busca respeitados, como Googlebot e Bingbot, respeita isso, mas bots maliciosos podem ignorá-lo completamente. Não confie em robots.txt para proteger conteúdos sensíveis ou privados. Use as configurações de controle de acesso para esse fim.
Devo incluir a URL do meu sitemap no arquivo robots.txt?
Sim. Incluir a URL do sitemap no seu arquivo robots.txt ajuda os rastreadores a descobrir todas as páginas do seu site de base de conhecimento de forma eficiente. Adicione usando o seguinte formato: Sitemap: https://yourdomain.com/sitemap.xml.