Eine robots.txt-Datei ist eine Textdatei, die am Kern Ihrer Wissensdatenbank platziert wird und mit Webcrawlern und automatisierten Agenten kommuniziert. Er legt fest, auf welche Seiten oder Abschnitte Ihrer Website-Crawler Zugriff erlaubt sind oder nicht. Suchmaschinen wie Google, Bing und Yandex lesen diese Datei, bevor sie Ihre Seite durchsuchen, um zu bestimmen, welche Inhalte sie indexieren sollten.
Ein Webcrawler, auch bekannt als Spider oder Spiderbot, ist ein automatisiertes Programm, das sich im Web durchquert und Informationen über Websites sammelt. Crawler öffnen Seiten, sammeln Daten wie Links, defekte Links, Sitemaps und HTML-Code und senden diese zur Indexierung an die Server ihrer Suchmaschine.
In Document360 ist die robots.txt-Datei direkt über die Einstellungen der Knowledge Base zugänglich und bearbeitbar. Sie gilt für Ihre gesamte Wissensdatenbank, nicht für einzelne Artikel oder Kategorien.
Wann sollte man Robots.txt
- Verhindern Sie, dass Suchmaschinen interne, administrative oder eingeschränkte Bereiche Ihrer Wissensdatenbank crawlen und indexieren.
- Blockieren Sie beispielsweise bestimmte Suchmaschinen vollständig daran, Ihre Seite zu indexieren, um zu kontrollieren, welche Suchmaschinen Ihre Inhalte anzeigen.
- Fügen Sie Crawl-Verzögerungsregeln hinzu, wenn Ihre Seite viel Traffic hat und Sie die durch Bot-Aktivitäten verursachte Belastung verringern möchten.
- Kombinieren Sie robots.txt mit Ihrer Sitemap, um Crawlern eine klare Übersicht darüber zu geben, was indexiert und was übersprungen werden soll.
Robots.txt steuert den Zugriff auf Crawler auf Standortebene. Um einzelne Artikel oder Kategorien aus den Suchergebnissen auszuschließen, verwenden Sie stattdessen die Einstellungen für Suchsichtbarkeit. Erfahren Sie mehr über die Sichtbarkeit in der Suche
Zugriff Robots.txt in Document360
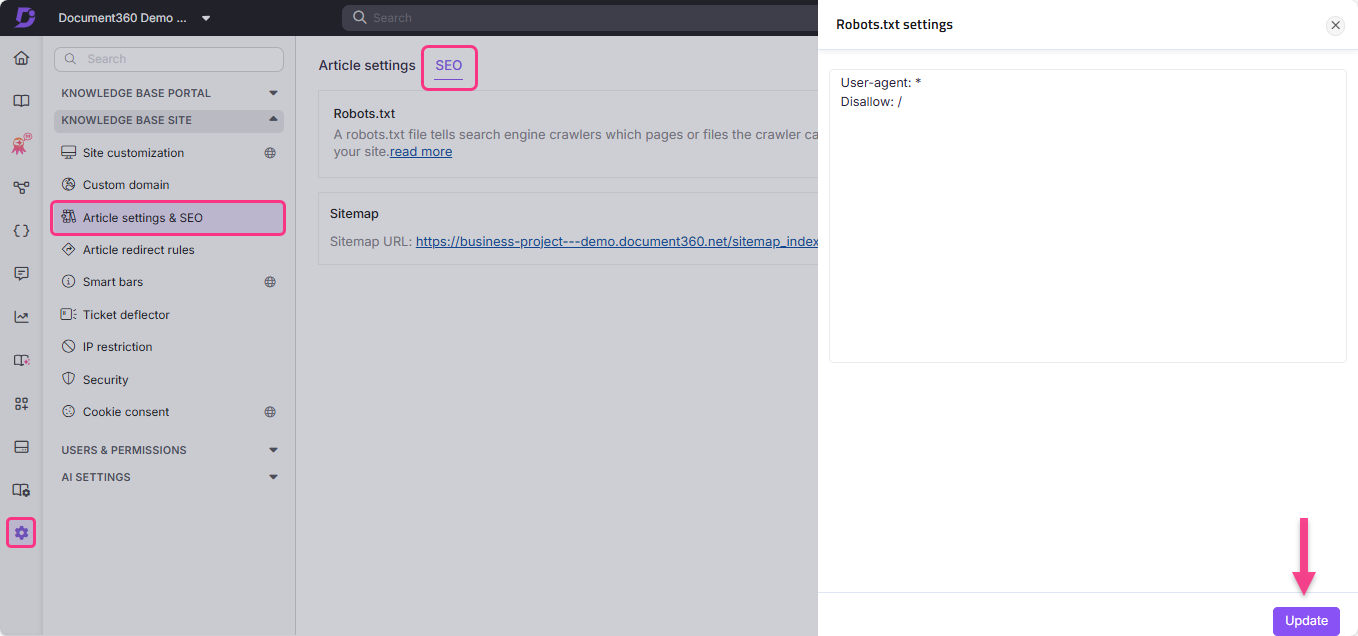
- Navigiere in der linken Navigationsleiste zu Einstellungen () ().
- Gehe zur Knowledge Base-Seite > Artikeleinstellungen und zum SEO -> -Reiter SEO.
- Finde Robots.txt und klicke auf Bearbeiten. Das Einstellungsfeld Robots.txt erscheint.
- Geben Sie Ihre Regeln ein.
- Klicken Sie auf Aktualisieren.
Gemeinsame Robots.txt Regeln
Blockiere alle Crawler auf einem bestimmten Weg
Nutze dies, um zu verhindern, dass Crawler auf Admin-Daten oder eingeschränkte Bereiche zugreifen.
User-agent: *
Disallow: /admin/
Sitemap: https://example.com/sitemap.xml
User-agent: *Die Regel gilt für alle Crawler.Disallow: /admin/verhindert, dass Crawler auf den Admin-Pfad zugreifen.Sitemap:stellt die Sitemap-URL bereit, damit Crawler alle indexierten Seiten effizient entdecken können.
Blockieren Sie eine bestimmte Suchmaschine
Nutzen Sie dies, um zu verhindern, dass eine bestimmte Suchmaschine Ihre Seite crawlt.
User-agent: Bingbot
Disallow: /
User-agent: Bingbotzielt nur auf den Bing-Suchmaschinen-Crawler ab.Disallow: /verhindert, dass Bingbot irgendeine Seite auf der Seite crawlt.
Fügen Sie eine Kriechverzögerung hinzu
Nutzen Sie dies, um die Crawl-Geschwindigkeit von Bots zu verlangsamen, wenn Ihre Seite unter hoher Verkehrslast steht.
User-agent: *
Crawl-delay: 10
Crawl-delay: 10weist Crawler an, zwischen den Anfragen 10 Sekunden zu warten.
Best Practices
- Fügen Sie Ihre Sitemap-URL immer in die robots.txt-Datei ein, damit Crawler Ihre indexierten Seiten leicht entdecken können.
- Blockseiten, die für Suchmaschinennutzer keinen Wert bieten, wie Admin-Pfade, Login-Seiten oder doppelte Inhaltspfade.
- Verwenden Sie robots.txt nicht als Sicherheitsmaßnahme. Es handelt sich um eine öffentliche Datei und verhindert keinen unbefugten menschlichen Zugriff. Nutze dafür die Zugangskontrolleinstellungen.
- Vermeiden Sie es, CSS- oder JavaScript-Dateien zu blockieren, die Suchmaschinen benötigen, um Ihre Seiten zu rendern und zu verstehen.
- Befolgen Sie die Formatrichtlinien von Google Search Central , um sicherzustellen, dass Ihre Datei gültig ist.
- Testen Sie Ihre robots.txt Regeln mit dem robots.txt-Tester der Google Search Console, bevor Sie Änderungen bereitstellen.
FAQ
Was ist der Unterschied zwischen den Robots.txt- und Such-Sichtbarkeitseinstellungen in Document360?
Robots.txt gilt auf Seitenebene und steuert, auf welche Pfade oder Abschnitte Crawler in deiner gesamten Wissensdatenbank zugreifen können. Suchsichtbarkeitseinstellungen gelten auf Artikel- oder Kategorieebene und ermöglichen es Ihnen, bestimmte Inhalte unabhängig von externen Suchmaschinen, der Suchleiste der Wissensdatenbank oder der Eddy-AI-Unterstützung auszuschließen. Nutze beides zusammen für eine präzise Kontrolle darüber, was indexiert wird.
Wie entferne ich mein Document360-Projekt aus dem Google-Suchindex?
Gehe zu Einstellungen () > Wissensdatenbank-Seite > Artikeleinstellungen und SEO -> SEO-Reiter , klicke auf Bearbeiten in Robots.txt, füge den folgenden Code ein und klicke auf Aktualisieren.
User-Agent: Googlebot
Disallow: /
Wie kann ich verhindern, dass Tag-Seiten von Suchmaschinen indexiert werden?
Gehe zu Einstellungen () > Knowledge Base-Seite > Artikeleinstellungen und SEO > SEO-Tab , klicke in Robots.txt auf Bearbeiten , füge den folgenden Code ein und klicke auf Aktualisieren.
User-agent: *
Disallow: /docs/en/tags/
Verhindert Robots.txt, dass alle Crawler auf blockierte Seiten zugreifen?
Robots.txt ist ein freiwilliger Standard. Die meisten seriösen Suchmaschinen-Crawler wie Googlebot und Bingbot respektieren es, aber böswillige Bots ignorieren es möglicherweise komplett. Verlassen Sie sich nicht darauf, dass robots.txt sensible oder private Inhalte schützen. Nutze dafür die Zugriffskontrolleinstellungen.
Sollte ich meine Sitemap-URL in die robots.txt-Datei aufnehmen?
Ja. Die Aufnahme der Sitemap-URL in Ihre robots.txt-Datei hilft Crawlern, alle Seiten Ihrer Wissensdatenbank effizient zu entdecken. Fügen Sie es in folgendem Format hinzu: Sitemap: https://yourdomain.com/sitemap.xml.