Un fichier robots.txt est un fichier texte placé à la racine de votre site de base de connaissances qui communique avec des robots d’indexation web et des agents automatisés. Il précise quelles pages ou sections de votre site sont autorisées ou non aux explorateurs d’indexation. Les moteurs de recherche tels que Google, Bing et Yandex lisent ce fichier avant d’explorer votre site pour déterminer quel contenu ils doivent indexer.
Un robot d’exploration web, également appelé spider ou spiderbot, est un programme automatisé qui navigue sur le web et collecte des informations sur des sites web. Les robots d’exploration ouvrent des pages, collectent des données telles que des liens, des liens cassés, des sites maps et du code HTML, puis les envoient aux serveurs de leur moteur de recherche pour indexation.
Dans Document360, le fichier robots.txt est accessible et modifiable directement depuis les paramètres du site de la base de connaissances. Cela s’applique à l’ensemble de votre site de base de connaissances, pas aux articles ou catégories individuelles.
Quand utiliser Robots.txt
- Empêchez les moteurs de recherche d’explorer et d’indexer les sections internes, administratives ou restreintes de votre base de connaissances.
- Bloquez par exemple certains moteurs de recherche qui indexent entièrement votre site afin de contrôler quels moteurs de recherche mettent en avant votre contenu.
- Ajoutez des règles de délai d’exploration lorsque votre site connaît un trafic élevé et que vous souhaitez réduire la charge causée par l’activité des bots.
- Associez-robots.txt à votre plan de site pour donner aux robots d’exploration une carte claire de ce qu’il faut indexer et ce qu’il faut sauter.
Robots.txt contrôle l’accès au crawler au niveau du site. Pour exclure des articles ou catégories individuels des résultats de recherche, utilisez plutôt les paramètres de visibilité de recherche. En savoir plus sur la visibilité dans la recherche
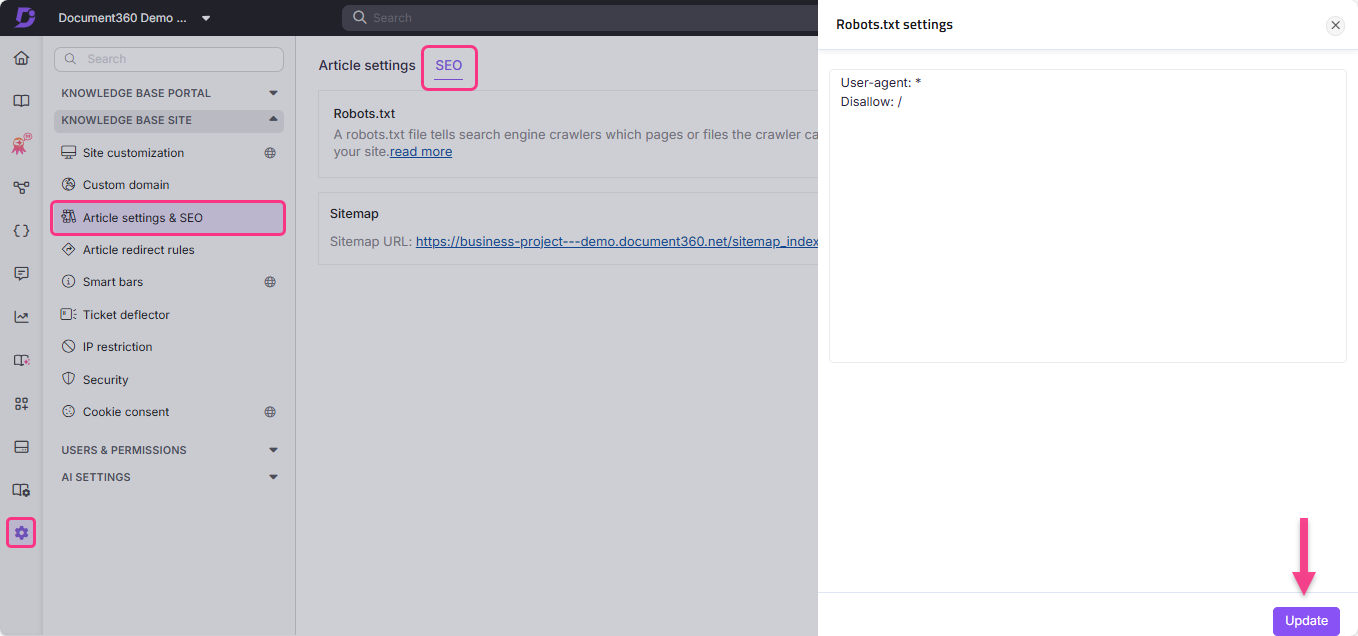
Accéder Robots.txt dans Document360
- Naviguez dans Paramètres () dans la barre de navigation de gauche.
- Allez sur le site de la base de connaissances > Paramètres d’article et SEO > onglet SEO .
- Localisez Robots.txt et cliquez sur Modifier. Le panneau de réglages Robots.txt apparaît.
- Saisis tes règles.
- Cliquez sur Mettre à jour.
Règles de Robots.txt communes
Bloquez tous les rampeurs sur un chemin spécifique
Utilisez cela pour empêcher les robots d’accès aux données d’administration ou aux sections restreintes.
User-agent: *
Disallow: /admin/
Sitemap: https://example.com/sitemap.xml
User-agent: *Applique la règle à tous les crawlers.Disallow: /admin/empêche les robots d’accès au chemin administrateur.Sitemap:fournit l’URL de la carte du site afin que les robots puissent découvrir efficacement toutes les pages indexées.
Bloquez un moteur de recherche spécifique
Utilisez cela pour empêcher un moteur de recherche particulier d’explorer votre site.
User-agent: Bingbot
Disallow: /
User-agent: Bingbotcible uniquement le moteur de recherche Bing.Disallow: /empêche Bingbot d’explorer n’importe quelle page du site.
Ajouter un délai de rampage
Utilisez cela pour ralentir la vitesse de crawl des bots lorsque votre site est sous forte charge de trafic.
User-agent: *
Crawl-delay: 10
Crawl-delay: 10demande aux robots d’attendre 10 secondes entre les demandes.
Meilleures pratiques
- Incluez toujours l’URL de votre sitemap dans le fichier robots.txt afin que les robots puissent facilement découvrir vos pages indexées.
- Bloquez les pages qui n’apportent aucune valeur aux utilisateurs des moteurs de recherche, telles que les chemins d’administration, les pages de connexion ou les chemins de contenu en double.
- N’utilisez pas robots.txt comme mesure de sécurité. Il s’agit d’un dossier public et n’empêche pas l’accès non autorisé à l’humain. Utilisez les paramètres de contrôle d’accès pour cela.
- Évitez de bloquer les fichiers CSS ou JavaScript dont les moteurs de recherche ont besoin pour afficher et comprendre vos pages.
- Suivez les directives de format de Google Search Central pour vous assurer que votre fichier est valide.
- Testez vos règles de robots.txt avec le testeur robots.txt de Google Search Console avant de déployer les modifications.
FAQ
Quelle est la différence entre les paramètres de visibilité Robots.txt et de recherche dans Document360 ?
Robots.txt s’applique au niveau du site et contrôle quels chemins ou sections les robots peuvent accéder dans toute votre base de connaissances. Les paramètres de visibilité de recherche s’appliquent au niveau de l’article ou de la catégorie et vous permettent d’exclure un contenu spécifique des moteurs de recherche externes, de la barre de recherche de la base de connaissances ou de la recherche assistée par Eddy AI. Utilisez les deux ensemble pour un contrôle précis sur ce qui est indexé.
Comment retirer mon projet Document360 de l’index de recherche Google ?
Allez dans Paramètres () > site de la base de connaissances > Paramètres d’articles et SEO > onglet SEO , cliquez sur Modifier dans Robots.txt, collez le code suivant, puis cliquez sur Mettre à jour.
User-Agent: Googlebot
Disallow: /
Comment empêcher que les pages de balises soient indexées par les moteurs de recherche ?
Allez dans Paramètres () > site de la base de connaissances > Paramètres d’article et SEO > onglet SEO , cliquez sur Modifier dans Robots.txt, collez le code suivant, puis cliquez sur Mettre à jour.
User-agent: *
Disallow: /docs/en/tags/
Est-ce Robots.txt empêche tous les robots d’exploration d’accéder aux pages bloquées ?
Robots.txt est une norme volontaire. La plupart des moteurs de recherche réputés comme Googlebot et Bingbot la respectent, mais les bots malveillants peuvent l’ignorer complètement. Ne comptez pas sur robots.txt pour protéger des contenus sensibles ou privés. Utilisez les paramètres de contrôle d’accès à cet effet.
Dois-je inclure l’URL de ma carte de site dans le fichier robots.txt ?
Oui. Inclure l’URL de la carte du site dans votre fichier robots.txt aide les robots à explorer efficacement toutes les pages de votre base de connaissances. Ajoutez-le en utilisant le format suivant : Sitemap: https://yourdomain.com/sitemap.xml.