La détection de contenu en double est une fonctionnalité d’IA Eddy dans Document360 qui analyse vos articles publiés, identifie les blocs de texte répétés et recommande de les convertir en extraits réutilisables. Utilisez-le pour maintenir une source unique de vérité cohérente dans votre base de connaissances et réduire la charge de maintenance liée à la mise à jour du même contenu à plusieurs endroits.
Quand utiliser la détection de contenu en double
- Votre base de connaissances s’est développée au fil du temps — À mesure que le nombre d’articles augmente, le même texte explicatif a tendance à être copié-collé entre les articles. Utilisez cette fonction pour trouver et consolider ces blocs avant qu’ils ne divergent.
- Vous standardisez le contenu pour la réutilisation — Si votre équipe adopte une approche axée sur les extraits d’abord, ce scan vous donne une liste prête à faire de candidats à convertir.
- Vous avez mis à jour un contenu central — Après avoir changé le nom d’un produit, un processus ou une politique, scannez pour trouver tous les articles où l’ancien texte était dupliqué et mettez-les à jour en une seule action.
- Vous voulez réduire les tickets de support causés par des informations contradictoires — Le contenu en double qui ne se synchronise pas crée de la confusion chez les lecteurs. La convertir en extrait garantit que chaque article affiche toujours la dernière version.
Avant que tu commences
- Seuls les administrateurs, propriétaires ou utilisateurs disposant des autorisations concernées sous des rôles personnalisés peuvent activer la détection de contenu en double.
- Seuls les utilisateurs ayant un accès à jour au module de ressources de contenu peuvent initier des scans.
- La détection de contenu en double prend actuellement en charge uniquement le contenu en anglais.
- Les articles publiés et les brouillons sont numérisés pour détecter la duplication du contenu.
- Vous pouvez effectuer un maximum de 4 scans manuels par mois. La limite se réinitialise le 1er de chaque mois. Une fois atteinte, l’option de balayage est désactivée jusqu’au prochain redémarrage.
- Les scans peuvent être effectués manuellement à tout moment. De plus, un scan programmé s’exécute automatiquement chaque mois
- Les articles auxquels vous n’avez pas accès n’apparaîtront pas dans les résultats des scans.
Quel contenu est scanné ?
Le balayage analyse uniquement les paragraphes en texte brut. Un paragraphe doit compter entre 50 et 4 000 caractères et contenir au moins 3 phrases pour être éligible. Les types de contenu suivants sont exclus du balayage :
| Type de contenu exclu | Notes |
|---|---|
| Listes | Ordonnés et non ordonnés |
| Tableaux | Tout le contenu du tableau |
| Rappels | Infos, avertissements, boîtes d’erreur |
| Accordéons et FAQ | Blocs de contenu effondrés |
| Tabs | Sections de contenu à onglets |
| Éléments médiatiques | Images, vidéos, GIFs |
| Contenu avec hyperliens | Tout paragraphe contenant un lien |
| Paragraphes avec variables | Contenu dynamique des variables |
| Contenu conditionnel | Blocs verrouillés par public ou par rôle |
| Guides étape par étape | Pages de contenu procéduralement |
| Arbres de décision | Pages de contenu embranchées |
| Pages personnalisées | Types de pages non standards |
Un extrait n’est suggéré que lorsque le score de correspondance est de 80 % ou plus, calculé comme : (Vector Score × 70%) + (ROUGE Score × 30%) ÷ 100. Les suggestions sont listées par ordre décroissant selon le nombre de fois où le double apparaît.
Activer la détection de contenu en double
- Dans le portail de la base de connaissances, allez dans Paramètres (⚙) > Paramètres IA > Paramètres IA d’Eddy.
- Faites défiler jusqu’à l’accordéon de la suite AI Premium .
- Activez la détection de contenu en double.
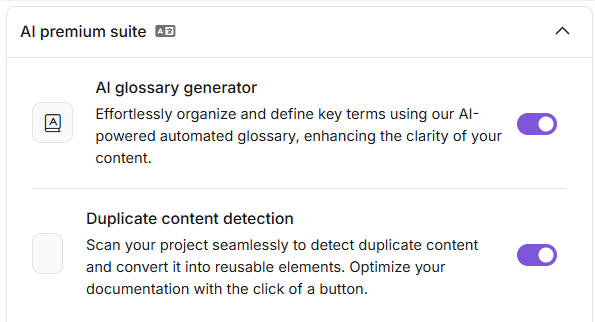
Une fois activé, vous pouvez lancer des analyses et consulter les rapports depuis la page Extraits ou la page Impulsion des connaissances .
Faites un scan
Extrait de la page Snippets
- Naviguez vers les outils de contenu > ressources de contenu > extraits.
- Localisez la bannière de détection de contenu en double en haut de la page.
- Cliquez sur Trouver des doublons pour lancer le scan (lors de la première utilisation). Si un scan précédent existe, cliquez à nouveau sur Scan.
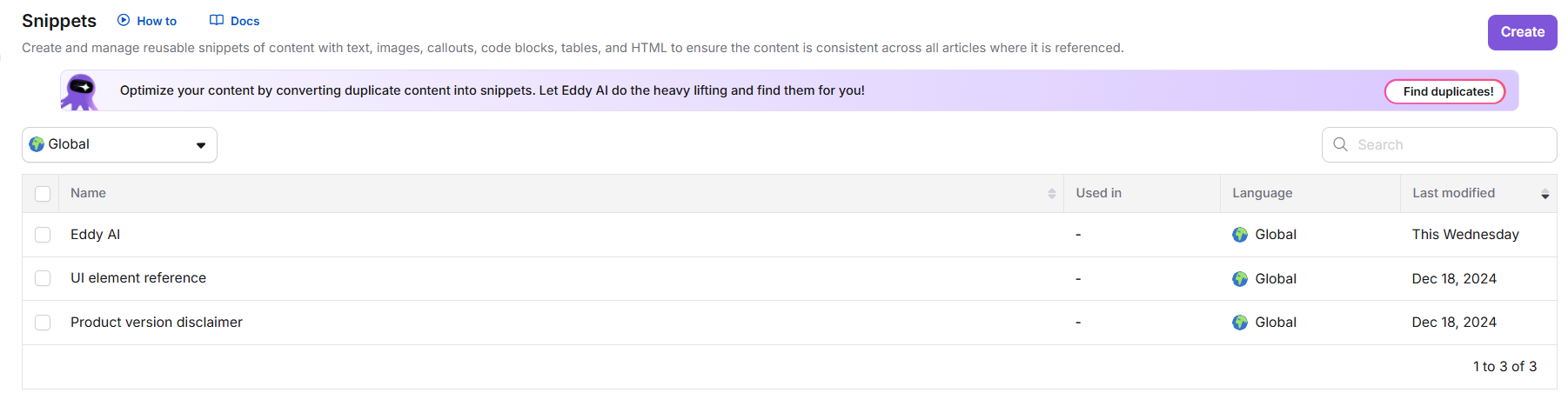
- Une fois le scan terminé, cliquez sur Suggestion de Réviser pour ouvrir le rapport de contenu en double.
D’après la page Impulsion de connaissances
- Dans le portail de la base de connaissances, cliquez sur l’icône impulsion des connaissances dans la barre de navigation de gauche.
- Dans la section Détection de contenu en double , cliquez sur Scanner maintenant.
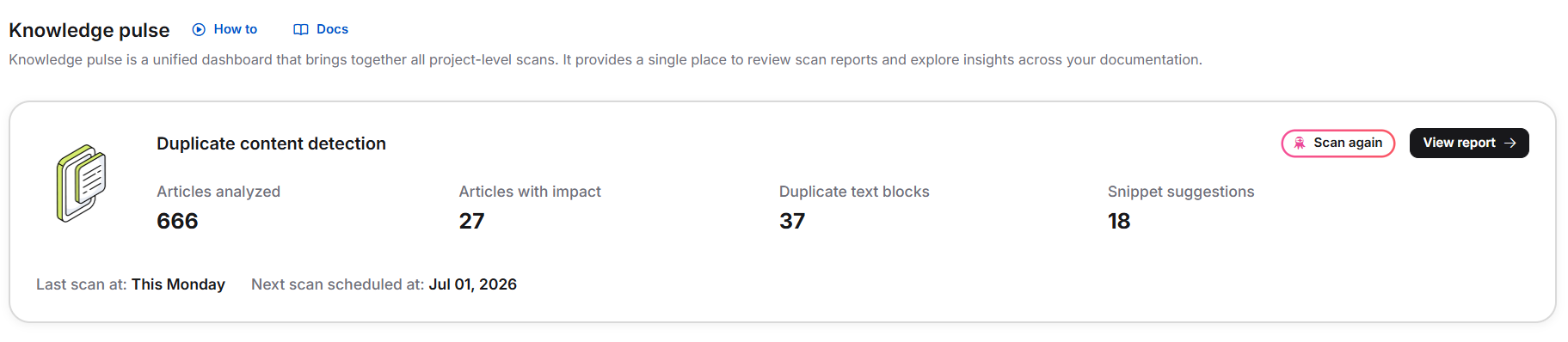
Une fois le scan terminé, les indicateurs suivants sont affichés :
| Métrique | Description |
|---|---|
| Articles analysés | Nombre total d’articles publiés numérisés |
| Articles à impact | Articles contenant au moins un bloc de texte en double |
| Blocs de texte en double | Nombre total d’instances en double identifiées |
| Suggestions de extraits | Nombre d’extraits qu’Eddy AI recommande de créer |
| Dernière date de scan | Quand le dernier scan a été effectué |
| Date de scan disponible suivante | Quand le prochain scan peut être lancé |
- Cliquez sur Voir le rapport pour ouvrir les résultats détaillés, ou Scanner à nouveau pour relancer la détection.
Pour voir quels articles composent le nombre d’articles impactés, cliquez sur Voir le rapport. Chaque entrée dans l’onglet Duplicates identifiés liste les articles où ce contenu apparaît.
Examiner et agir sur le rapport
Le rapport de détection de contenu en double comporte deux onglets : Duplicates identifiés et Duplicatas ignorées.
onglet Duplicatas identifiés
Le panneau de gauche liste tous les doublons identifiés par Eddy AI. Chaque entrée indique combien de fois le contenu apparaît et sur combien d’articles — par exemple, « Ce contenu apparaît 16 fois dans 10 articles. »
Utilisez la liste déroulante du filtre pour réduire la liste :
| Filtre | Ce qu’il montre |
|---|---|
| Tous | Chaque suggestion de doublon, quel que soit son statut |
| Nouveau | Duplicatas pour lesquels aucun extrait n’existe encore |
| Existant | Des doublons qui correspondent au contenu déjà sauvegardé en extrait |
La dernière version publiée de chaque article est toujours utilisée pour la comparaison. Si un article ou un extrait a été modifié depuis le dernier scan, une invite vous demandera de rescanner avant d’agir sur la suggestion.
Cliquez sur n’importe quelle entrée pour ouvrir le panneau de détail à droite, où vous pouvez :
- Modifier le nom suggéré du extrait.
- Confirmez ou changez la langue cible (l’anglais par défaut).
- Cliquez sur Ignorer pour déplacer l’entrée dans l’onglet Duplicates ignorés.
- Consultez le pourcentage de correspondance pour chaque doublon.
- Cliquez sur Ajouter un extrait et mettre à jour des articles pour appliquer l’extrait sur tous les articles listés.
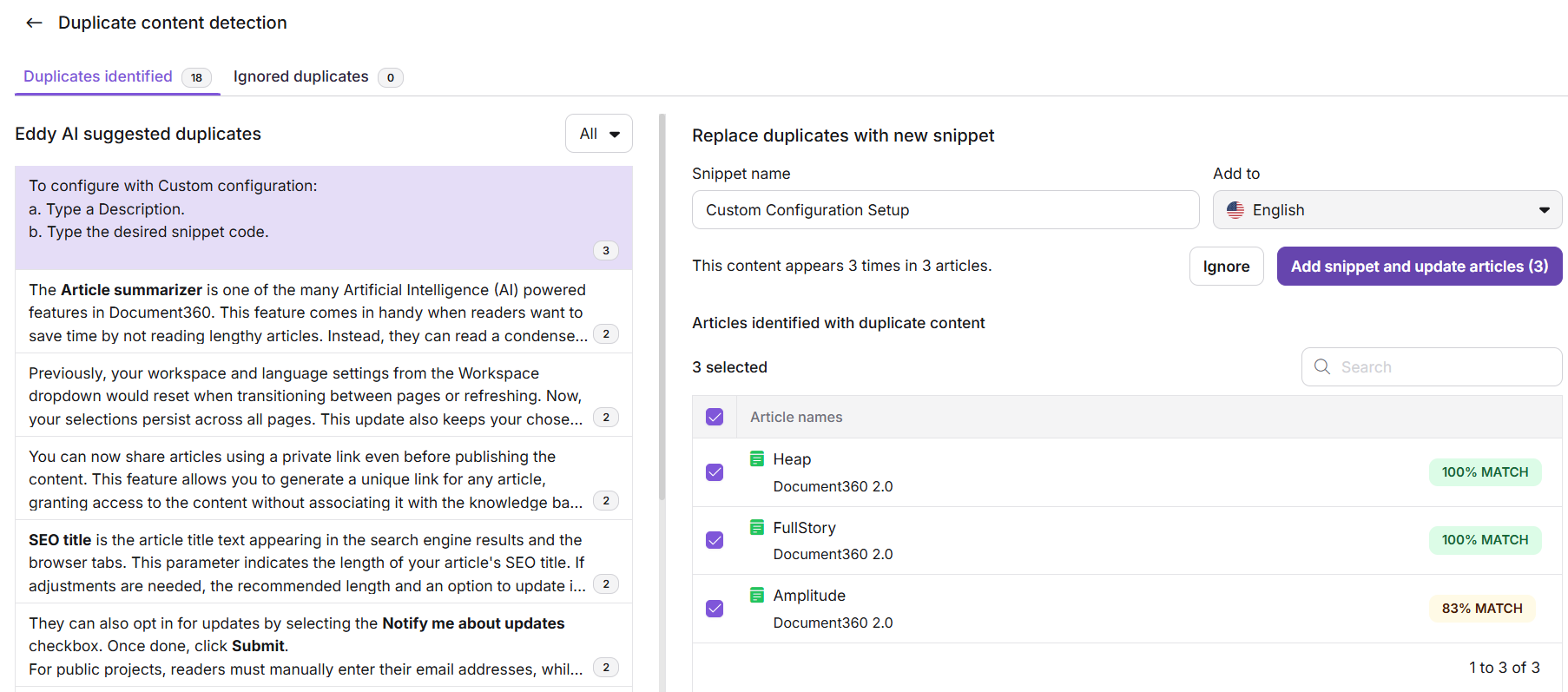
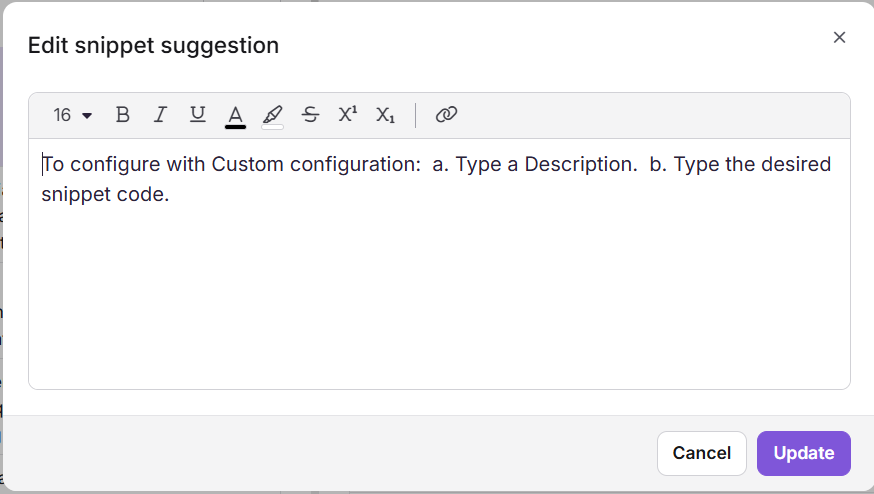
Édit : un extrait suggéré
-
Cliquez sur l’icône Modifier (✏) à côté du contenu suggéré.
-
Dans la boîte de dialogue de suggestions d’extraits d’édition , modifier le texte et appliquer la mise en forme à l’aide des outils disponibles.
Lorsque vous modifiez le contenu, le pourcentage de correspondance se recalcule automatiquement. Même si le score descend en dessous de 80 %, le pourcentage mis à jour reste visible pour comparaison. La liste de suggestions ne se rafraîchit pas — elle continue de refléter les correspondances originales identifiées avant la modification.
-
Cliquez sur Mettre à jour pour sauvegarder vos modifications.
Aperçu des modifications avant de postuler
Avant d’appliquer un extrait, vous pouvez vérifier à quoi ressemblera chaque article après le changement :
-
Dans l’onglet Duplicates identifiés , survolez un article dans le panneau de droite et cliquez sur l’icône (i) pour en voir les détails.
-
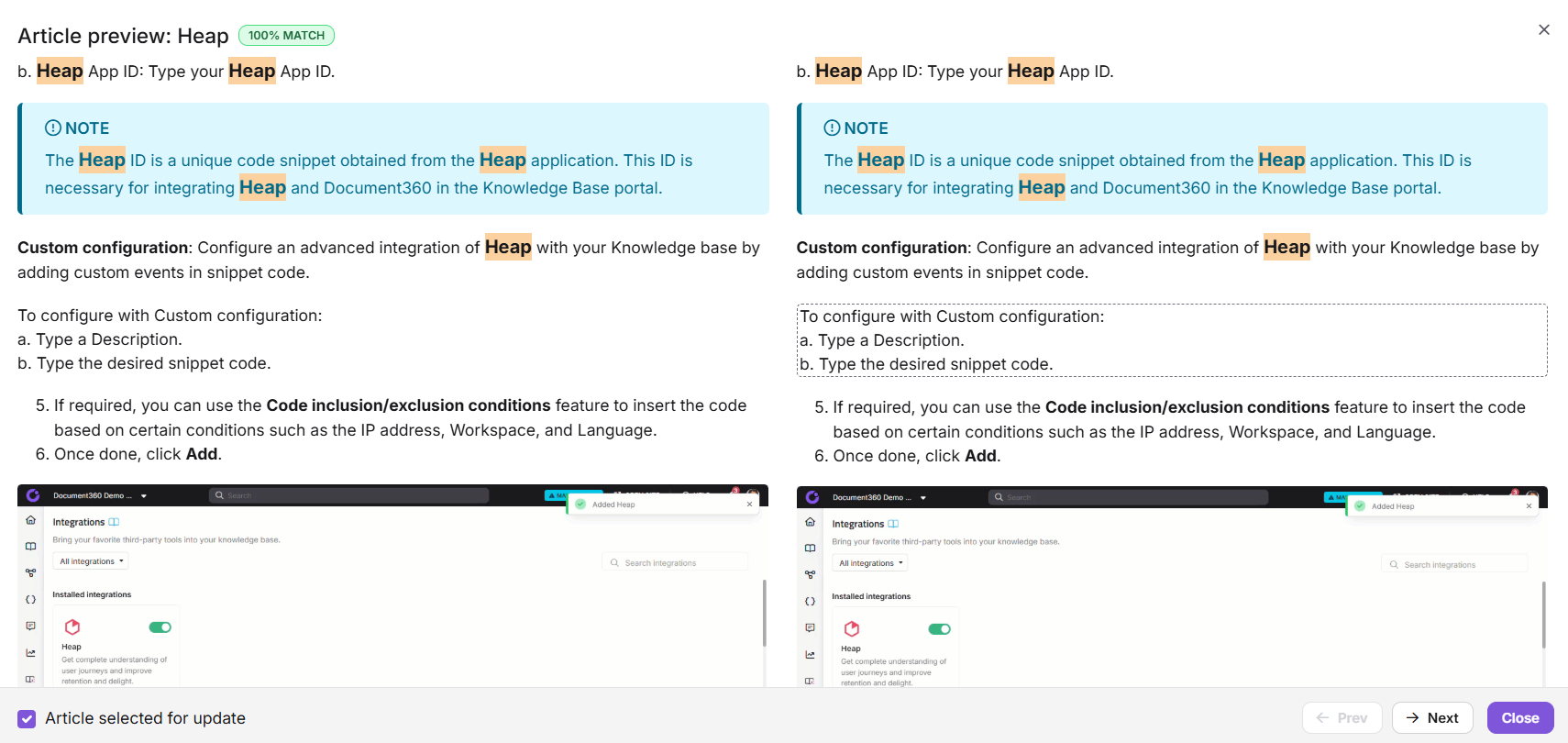
Cliquez sur Aperçu pour ouvrir la vue divisée.
Le côté gauche affiche le contenu original de l’article. Le côté droit affiche la version mise à jour avec le extrait appliqué. Le texte supprimé est surligné en rouge, le texte ajouté en vert, et la mise en forme est modifiée en bleu. Le extrait inséré est encadré d’un rectangle pointillé sur le côté droit.
-
Utilisez Suivant et Précédent pour passer d’un aperçu de l’article. Pour exclure un article spécifique de la mise à jour, décochez la case Article sélectionnée pour mise à jour pour cet article.
Lorsqu’un extrait est appliqué à un article publié, celui-ci est immédiatement republié. Pour les articles provisoires, les modifications sont appliquées dans la même version, sauf si le brouillon est verrouillé. Une note intitulée « Publié via Snippets » est ajoutée à l’historique des versions, et l’action est enregistrée lors de l’audit de l’équipe.
Appliquez le fragment
- Consultez l’aperçu et confirmez quels articles inclure.
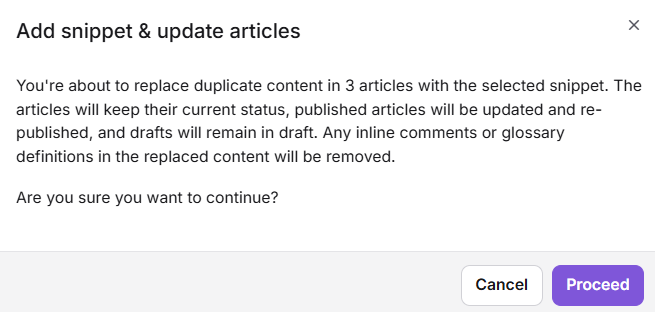
- Cliquez sur Ajouter un extrait et mettre à jour des articles.
- Cliquez sur Continuer dans la boîte de confirmation.
Un message de confirmation apparaît : « Extrait ajouté, et articles mis à jour avec succès. »
Lorsque le contenu en double est converti en extrait, tous les commentaires en ligne contenus dans ce contenu sont supprimés de l’article. Ils restent disponibles dans la section résolue du panneau des commentaires en ligne pour référence. Si le contenu contient un terme de glossaire, la définition du glossaire liée à ce terme est également supprimée lors du remplacement — le terme demeure, mais sa définition n’apparaîtra plus. Vous êtes informé de cela lors de la confirmation de mise à jour.
onglet Duplicatas ignorés
L’onglet Duplicatas ignorés liste les entrées que vous avez supprimées en utilisant l’option Ignorer . Suggestions ignorées :
- Impossible à éditer.
- Persister après un nouveau scan — si la liste des articles affectés change, l’entrée est mise à jour pour refléter la liste des nouveaux articles, mais la suggestion reste ignorée.
- Peut être restauré à tout moment en cliquant sur Déplacer pour ouvrir la liste.
Limitations
| Limite | Valeur | Notes |
|---|---|---|
| Scans par mois | 4 | Réinitialisation le 1er de chaque mois |
| Déclencheur de balayage | Manuels uniquement | Non automatisé |
| Longueur minimale des paragraphes | 50 caractères | Les paragraphes plus courts sont exclus |
| Longueur maximale des paragraphes | 4 000 caractères | Les paragraphes plus longs sont exclus |
| Peine minimale | 3 phrases | Les paragraphes avec moins de phrases sont exclus |
| Score minimum de match | 80% | Les suggestions en dessous de ce seuil ne sont pas affichées |
| Prise en charge des langues | Anglais uniquement | Les autres versions linguistiques ne sont pas numérisées |
| Éligibilité à l’article | Articles publiés uniquement | Les brouillons et articles inédits sont exclus |
| Type d’éditeur pour un extrait | Cela dépend des articles concernés | Si tous sont Markdown, le fragment est Markdown ; si certains utilisent Advanced WYSIWYG, le extrait est Advanced WYSIWYG |
Meilleures pratiques
- Aperçu avant de postuler — Utilisez l’aperçu en vue partagée pour vérifier chaque article avant de vous engager. C’est particulièrement important pour les articles publiés, qui sont republiés immédiatement lorsqu’un extrait est appliqué.
- Postulez de manière sélective lorsque nécessaire — Vous n’avez pas besoin d’appliquer un extrait sur chaque article concerné en même temps. Décochez les articles qui nécessitent une relecture individuelle avant de continuer.
- Renommer les suggestions de fragments avant de sauvegarder — Les noms de extraits générés automatiquement sont souvent génériques. Renomme-les en quelque chose de descriptif (par exemple,
[Shared] Account deletion warning) pour qu’ils soient faciles à gérer dans le module Snippets plus tard. - Effectuez un scan après les mises à jour majeures du contenu — Si plusieurs articles ont été mis à jour depuis le dernier scan, rescannez avant d’agir sur les suggestions afin de vous assurer que le rapport reflète l’état actuel de votre base de connaissances.
- Modifier les extraits existants dans le module Extraits — Lorsqu’un doublon détecté correspond à un extrait existant, toute modification future de ce contenu doit être effectuée dans les outils de contenu > ressources de contenu > extraits, et non dans le rapport de détection de contenu en double.
- Espacez les scans de manière stratégique — Avec seulement 4 scans par mois, évitez de scanner immédiatement après chaque petit changement. Attendez qu’un ensemble significatif d’articles soit publié ou mis à jour.
FAQ
Que se passe-t-il si le contenu dupliqué détecté existe déjà sous forme de fragments ?
Eddy AI le signale toujours comme un doublon. Le contenu existant devient le contenu principal, un tag de fragment existant est affiché par rapport à la suggestion, et le pourcentage de correspondance est recalculé par rapport à ce fragment. Le contenu en double dans d’autres articles est remplacé par un extrait existant. Pour modifier l’extrait, allez dans le module Extraits — les modifications ne peuvent pas être effectuées depuis le rapport de Détection de contenu dupliqué.
Que se passe-t-il si un extrait ou un article est supprimé après le scan ?
Si le fragment est supprimé, la tentative de mise à jour d’un article en l’utilisant échoue et un message « Mise à jour échouée » apparaît — la suggestion est retirée de la liste. Si un article est supprimé après le scan, il n’apparaît plus dans la liste des articles impactés, mais le nombre initial d’occurrences (par exemple « 16 fois dans 10 articles ») reflète toujours les résultats du scan. L’article supprimé ne peut pas être sélectionné pour une mise à jour.
Que se passe-t-il si un article est modifié après le scan ?
L’aperçu montre : « On dirait que l’article a été mis à jour depuis le dernier scan. Le contenu en double suggéré n’est plus trouvé. Veuillez rescanner pour obtenir les derniers résultats. » L’article est désélectionné et désactivé dans l’aperçu par défaut. Si vous essayez de mettre à jour sans prévisualisation préalable, le message de résultat indiquera combien d’articles ont été mis à jour et combien ont échoué.
Est-ce que des articles clonés apparaissent dans le scan ?
Oui. Le scan s’exécute au niveau du projet. Les articles clonés — qu’ils soient créés dans le même espace de travail ou à travers différents espaces de travail — sont traités comme des articles séparés, et tout contenu en double apparaît comme une entrée distincte dans les résultats de la numérisation.