Duplicate Content Detection is een Eddy AI-functie in Document360 die je gepubliceerde artikelen scant, herhaalde tekstblokken identificeert en aanbeveelt deze om te zetten in herbruikbare fragmenten. Gebruik het om een consistente, één bron van waarheid te behouden in je kennisbasis en de onderhoudskosten van het updaten van dezelfde inhoud op meerdere plaatsen te verminderen.
Wanneer te gebruiken Duplicate content detection
- Je kennisbasis is in de loop der tijd gegroeid — Naarmate het aantal artikelen toeneemt, wordt dezelfde verklarende tekst vaak gekopieerd en geplakt over artikelen. Gebruik deze functie om die blokken te vinden en te consolideren voordat ze uit elkaar gaan.
- Je standaardiseert content voor hergebruik — Als je team overgaat op een snippets-first aanpak, geeft deze scan je een kant-en-klare lijst met kandidaten om te converteren.
- Je hebt een kerninhoud bijgewerkt — Na het wijzigen van een productnaam, proces of beleid, scan je alle artikelen waarin de oude bewoording is gedupliceerd en werk je ze in één actie bij.
- Je wilt supporttickets verminderen door tegenstrijdige informatie — Dubbele inhoud die niet synchroon loopt, zorgt voor verwarring bij lezers. Het omzetten in een fragment zorgt ervoor dat elk artikel altijd de nieuwste versie toont.
Voordat je begint
- Alleen beheerders, eigenaren of gebruikers met de relevante rechten onder aangepaste rollen kunnen Duplicate Content Detection inschakelen.
- Alleen gebruikers met update-toegang tot de Content resources-module kunnen scans starten.
- Duplicate Content Detection ondersteunt momenteel alleen Engelse inhoud.
- Zowel gepubliceerde als conceptartikelen worden gescand op duplicatie van inhoud.
- Je kunt maximaal 4 handmatige scans per maand uitvoeren. De limiet wordt op de 1e van elke maand gereset. Eenmaal bereikt wordt de scanoptie uitgeschakeld tot de volgende reset.
- Scans kunnen op elk moment handmatig worden uitgevoerd. Daarnaast wordt er elke maand automatisch een geplande scan uitgevoerd
- Artikelen waar je geen toegang toe hebt, verschijnen niet in de scanresultaten.
Welke inhoud wordt gescand?
De scan analyseert alleen platte tekstparagrafen. Een alinea moet tussen de 50 en 4.000 tekens bevatten en minstens 3 zinnen bevatten om in aanmerking te komen. De volgende inhoudstypen zijn uitgesloten van scan:
| Uitgesloten inhoudstype | Noten |
|---|---|
| Lijsten | Geordend en ongeordend |
| Tabellen | Alle tabelinhoud |
| Oproepen | Info, waarschuwing, foutmeldingen |
| Accordeons en veelgestelde vragen | Ingevouwen contentblokken |
| Tabs | Tabbladen met inhoud |
| Media-elementen | Afbeeldingen, video's, GIF's |
| Inhoud met hyperlinks | Elke alinea met een link |
| Paragrafen met variabelen | Dynamische variabele-inhoud |
| Voorwaardelijke inhoud | Publiek- of rolafschermde blokken |
| Stapsgewijze handleidingen | Pagina's met procedurele inhoud |
| Beslissingsbomen | Vertakkende inhoudspagina's |
| Aangepaste pagina's | Niet-standaard paginatypen |
Een fragment wordt alleen voorgesteld wanneer de matchscore 80% of hoger is, berekend als: (Vector Score × 70%) + (ROUGE Score × 30%) ÷ 100. Suggesties worden in aflopende volgorde gerangschikt naar het aantal keren dat de duplicaat verschijnt.
Schakel detectie van dubbele inhoud in
- Navigeer in het Knowledge Base-portaal naar Instellingen (⚙) > AI-instellingen > Eddy AI-instellingen.
- Scroll naar beneden naar de AI Premium suite accordeon.
- Zet detectie van dubbele inhoud aan.
Zodra ingeschakeld, kun je scans starten en rapporten bekijken vanaf de Snippets-pagina of de Knowledge pulse-pagina .
Doe een scan
Van de Snippets-pagina
- Navigeer naar Contenttools > Contentbronnen > Snippets.
- Zoek de banner voor het herkennen van dubbele inhoud bovenaan de pagina.
- Klik op Duplicaten zoeken om de scan te starten (bij eerste gebruik). Als er een eerdere scan bestaat, klik dan opnieuw op Scannen.
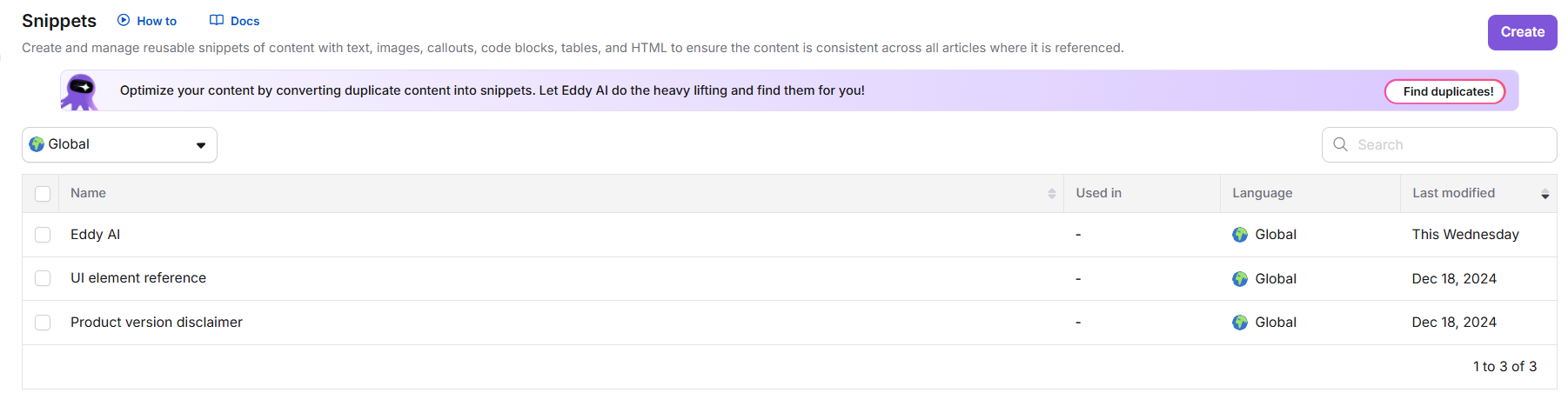
- Zodra de scan is voltooid, klik je op Suggestie beoordelen om het rapport over dubbele inhoud te openen.
Van de Kennispuls-pagina
- Klik in het Kennisbankportaal op het Kennispuls-icoon in de linker navigatiebalk.
- Klik in de sectie Duplicate content detection op Nu scannen.
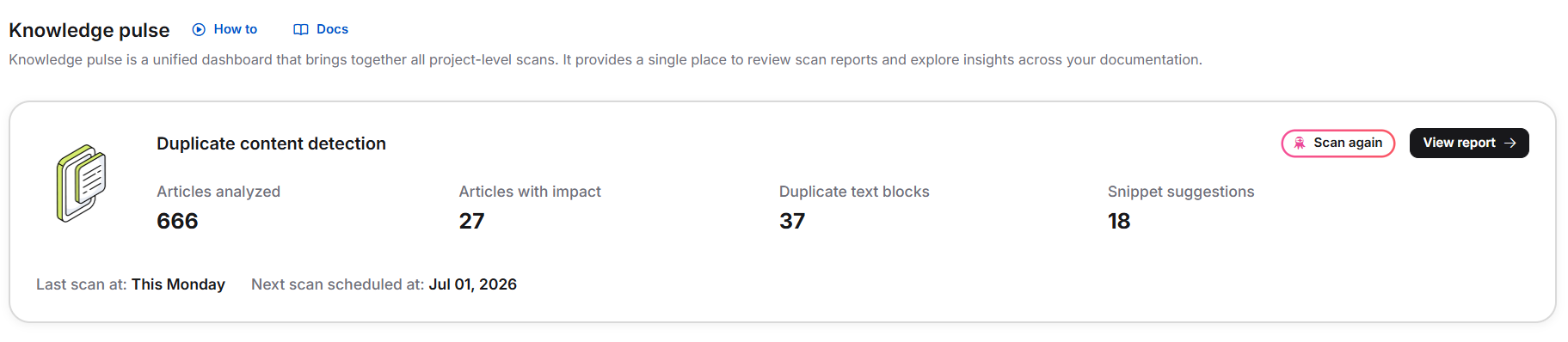
Zodra de scan is voltooid, worden de volgende metrieken weergegeven:
| Metriek | Beschrijving |
|---|---|
| Geanalyseerde artikelen | Totaal aantal gepubliceerde artikelen die zijn gescand |
| Artikelen met impact | Artikelen die ten minste één duplicaat tekstblok bevatten |
| Dubbele tekstblokken | Totaal aantal geïdentificeerde dubbele gevallen |
| Suggesties voor fragmenten | Aantal fragmenten dat Eddy AI aanbeveelt te maken |
| Laatste scandatum | Toen de meest recente scan werd uitgevoerd |
| Volgende beschikbare scandatum | Wanneer de volgende scan kan worden gestart |
- Klik op Rapport bekijken om de gedetailleerde resultaten te openen, of op opnieuw scannen om detectie opnieuw uit te voeren.
Om te zien welke artikelen deel uitmaken van het aantal Getroffen artikelen, klik op Rapport bekijken. Elke vermelding in het tabblad Duplicates identified vermeldt de artikelen waarin die inhoud voorkomt.
Beoordeel en onderhandel het rapport
Het rapport Duplicate content detection heeft twee tabbladen: Duplicaten geïdentificeerd en Genegeerde duplicaten.
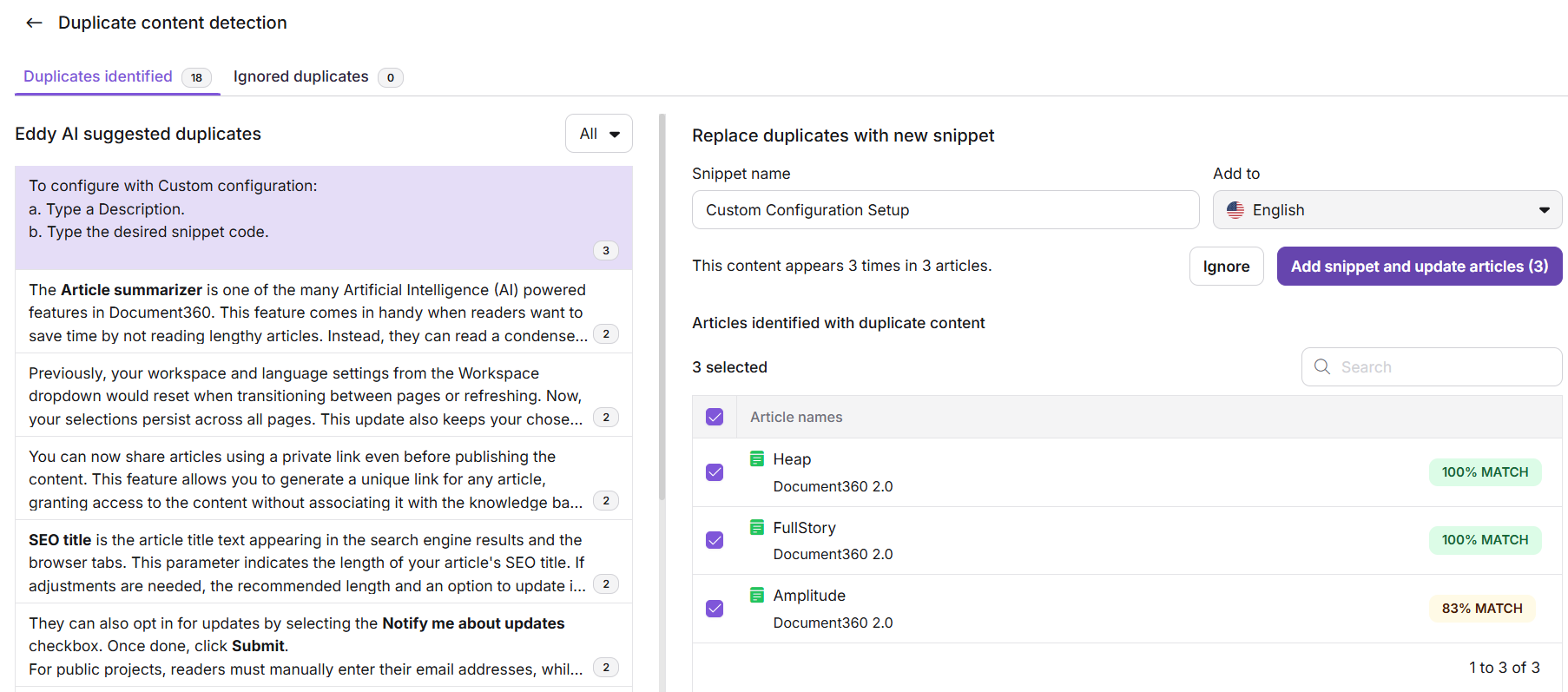
Tabblad Duplicaten geïdentificeerd
Het linkerpaneel geeft alle duplicaten weer die Eddy AI heeft geïdentificeerd. Elke vermelding toont hoe vaak de inhoud voorkomt en over hoeveel artikelen — bijvoorbeeld: "Deze inhoud komt 16 keer voor in 10 artikelen."
Gebruik het filter-dropdown om de lijst te verfijnen:
| Filter | Wat het laat zien |
|---|---|
| Allemaal | Elke dubbele suggestie, ongeacht status |
| Nieuw | Duplicaten waarvan er nog geen fragment bestaat |
| Bestaande | Duplicaten die overeenkomen met content die al als fragment is opgeslagen |
De laatst gepubliceerde versie van elk artikel wordt altijd gebruikt ter vergelijking. Als een artikel of fragment sinds de laatste scan is aangepast, zal een prompt je vragen om opnieuw te scannen voordat je op het voorstel reageert.
Klik op een willekeurige vermelding om het detailpaneel rechts te openen, waar je kunt:
- Bewerk de voorgestelde snippetnaam.
- Bevestig of verander de doeltaal (standaard Engels).
- Klik op Negeren om de vermelding naar het tabblad 'Genegeerde duplicaten' te verplaatsen.
- Bekijk de procentuele matchscore voor elke duplicaat.
- Klik op Voeg snippet toe en update artikelen om het snippet toe te passen op alle vermelde artikelen.
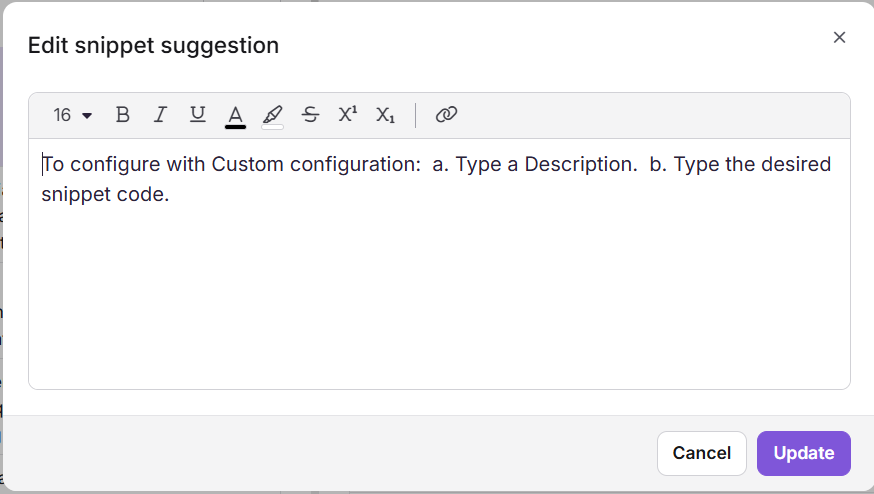
Een voorgestelde snippet bewerkt.
-
Klik op het pictogram Bewerken (✏) naast de voorgestelde inhoud.
-
Bewerk in het dialoog 'Edit snippet suggestion ' en pas de opmaak toe met de beschikbare tools.
Wanneer je de inhoud bewerkt, wordt het matchpercentage automatisch opnieuw berekend. Zelfs als de score onder de 80% zakt, blijft het bijgewerkte percentage zichtbaar voor vergelijking. De suggestielijst ververst niet — hij blijft de originele matches weergeven die vóór het bewerken zijn geïdentificeerd.
-
Klik op Bijwerken om je wijzigingen op te slaan.
Voorbeeldwijzigingen vóór aanvraag
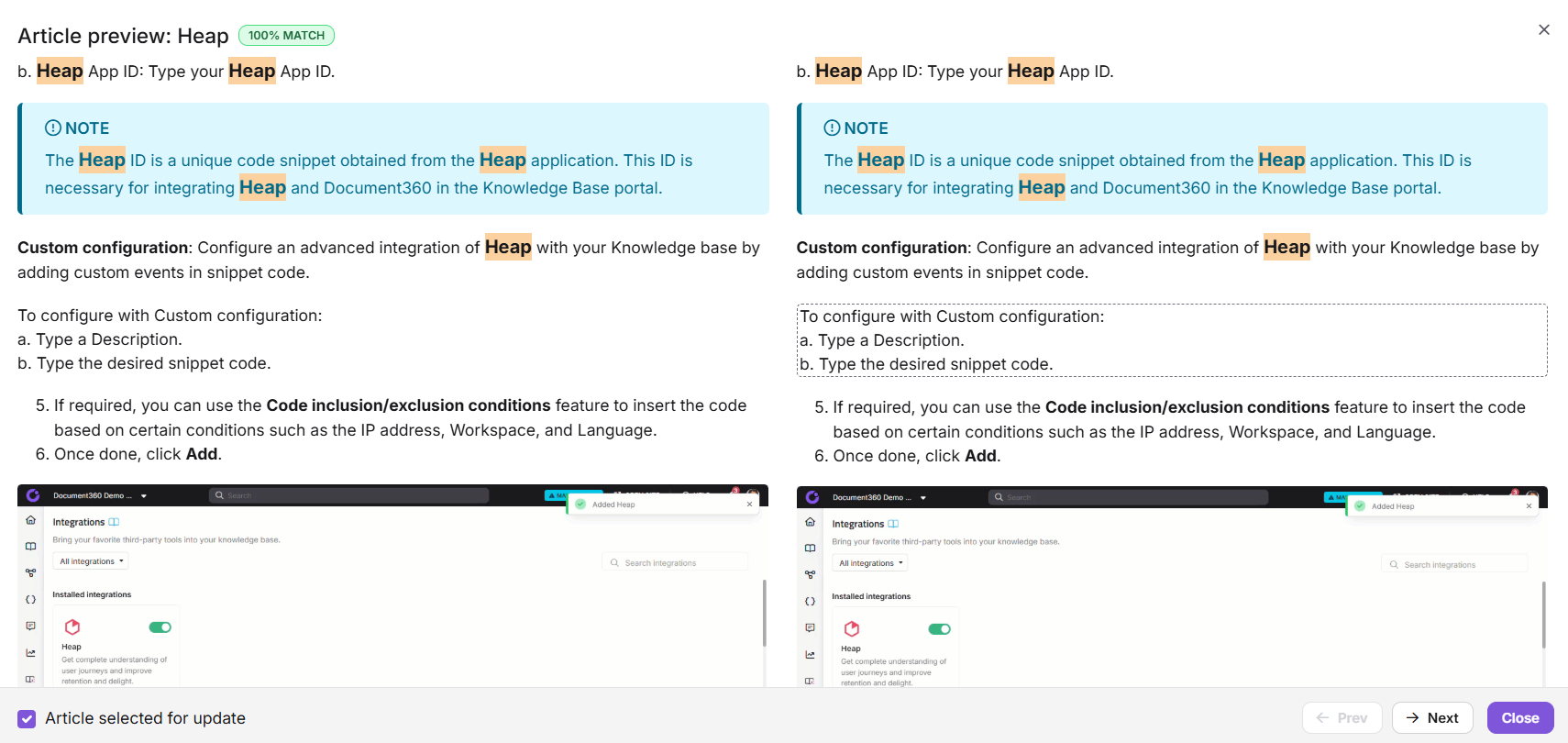
Voordat je een snippet toepast, kun je controleren hoe elk artikel eruit zal zien na de verandering:
-
In het tabblad Duplicates identified beweeg je met de hoef over een artikel in het rechterpaneel en klik je op het (i)-icoon om de details te bekijken.
-
Klik op Preview om de split view te openen.
De linkerkant toont de oorspronkelijke inhoud van het artikel. Aan de rechterkant staat de bijgewerkte versie met het fragment toegepast. Verwijderde tekst is rood gemarkeerd, toegevoegde tekst groen en opmaakwijzigingen blauw. Het ingevoegde fragment wordt aan de rechterkant omlijnd met een gestippelde rechthoek .
-
Gebruik Next en Prev om tussen artikelvoorbeelden te wisselen. Om een specifiek artikel uit te sluiten van de update, zet u het vakje 'Het voor update' geselecteerde vakje 'Artikel ' voor dat artikel uit het vinkje.
Wanneer een fragment wordt toegepast op een gepubliceerd artikel, wordt het artikel onmiddellijk opnieuw gepubliceerd. Voor conceptartikelen worden wijzigingen binnen dezelfde versie toegepast, tenzij het concept is vergrendeld. Een notitie getiteld "Gepubliceerd via Snippets" wordt toegevoegd aan de versiegeschiedenis en de actie wordt vastgelegd in teamauditing.
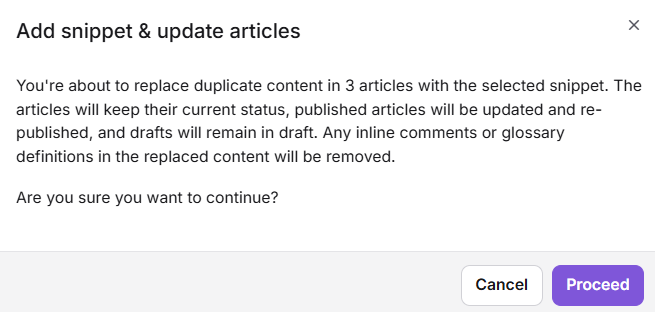
Pas het fragment toe
- Bekijk de preview en bevestig welke artikelen je moet toevoegen.
- Klik op Toevoegen van fragment en artikel bijwerken.
- Klik op Doorgaan in het bevestigingsmenu.
Er verschijnt een bevestigingsbericht: "Fragment toegevoegd, en artikelen succesvol bijgewerkt."
Wanneer dubbele inhoud wordt omgezet in een snippet, worden alle inline reacties binnen die inhoud uit het artikel verwijderd. Ze blijven beschikbaar in het opgeloste gedeelte van het Inline commentaarpaneel ter referentie. Als de inhoud een woordenlijst bevat, wordt de definitie van die woordenlijst die aan die term is gekoppeld ook verwijderd bij vervanging — de term blijft bestaan, maar de definitie zal niet meer voorkomen. Je wordt hierover op de hoogte gebracht tijdens de bevestiging van de update.
Tabblad voor genegeerde duplicaten
Het tabblad 'Genegeerde duplicaten' geeft vermeldingen die je hebt verwijderd met de optie Negeer . Genegeerde suggesties:
- Kan niet worden bewerkt.
- Blijf bestaan na een nieuwe scan — als de lijst met getroffen artikelen verandert, wordt de vermelding bijgewerkt om de nieuwe artikelenlijst weer te geven, maar de suggestie blijft genegeerd.
- Kan op elk moment worden hersteld door op Verplaatsen naar open lijst te klikken.
Beperkingen
| Limiet | Waarde | Noten |
|---|---|---|
| Scans per maand | 4 | Reset op de 1e van elke maand |
| Scan-trigger | Alleen handmatig | Niet geautomatiseerd |
| Minimale paragraaflengte | 50 tekens | Kortere alinea's zijn uitgesloten |
| Maximale lengte van de alinea | 4.000 tekens | Langere alinea's zijn uitgesloten |
| Minimale strafaantaling | 3 zinnen | Paragrafen met minder zinnen worden uitgesloten |
| Minimale wedstrijdscore | 80% | Suggesties onder deze drempel worden niet getoond |
| Taalondersteuning | Alleen Engels | Andere taalversies worden niet gescand |
| Artikelgeschiktheid | Alleen gepubliceerde artikelen | Concepten en niet-gepubliceerde artikelen zijn uitgesloten |
| Editor type voor snippet | Het hangt af van de geïmplineerde artikelen | Als alle Punten Markdown zijn, is het fragment Markdown; als iemand Advanced WYSIWYG gebruikt, is het fragment Advanced WYSIWYG |
Best practices
- Preview voordat je aanvraagt — Gebruik de split-view preview om elk artikel te verifiëren voordat je je committeert. Dit is vooral belangrijk voor gepubliceerde artikelen, die onmiddellijk worden hergepubliceerd zodra een fragment wordt toegepast.
- Pas selectief toe wanneer nodig — Je hoeft niet op elk betreffende artikel tegelijk een snippet toe te passen. Vink artikelen die individuele beoordeling nodig hebben weg voordat je verder gaat.
- Naamgeef snippet-suggesties opnieuw voordat je opslaat — Automatisch gegenereerde snippetnamen zijn vaak generiek. Geef ze een beschrijvende naam (bijvoorbeeld
[Shared] Account deletion warning) zodat ze later makkelijk te beheren zijn in de Snippets-module. - Voer een scan uit na grote inhoudsupdates — Als meerdere artikelen sinds de laatste scan zijn bijgewerkt, scan dan opnieuw voordat je op suggesties reageert om te zorgen dat het rapport de huidige stand van je kennisbank weerspiegelt.
- Bewerk bestaande snippets in de Snippets-module — Wanneer een gedetecteerd duplicaat overeenkomt met een bestaand snippet, moeten toekomstige bewerkingen aan die content worden uitgevoerd in Contenttools > Content resources > snippets, niet in het Duplicate Content Detection-rapport.
- Verspreid scans strategisch — Met slechts 4 scans per maand, vermijd direct scannen na elke kleine wijziging. Wacht tot er een betekenisvolle hoeveelheid artikelen is gepubliceerd of bijgewerkt.
FAQ
Wat gebeurt er als gedetecteerde dubbele inhoud al als fragment bestaat?
Eddy AI markeert het nog steeds als een duplicaat. De bestaande snippet-inhoud wordt de primaire content, een bestaande snippet-tag wordt weergegeven tegen de suggestie, en het matchpercentage wordt opnieuw berekend met dat snippet. Dubbele inhoud in andere artikelen wordt vervangen door het bestaande fragment. Om het fragment te bewerken, ga je naar de Snippets-module — bewerkingen kunnen niet worden gedaan vanuit het rapport Duplicate Content Detection.
Wat gebeurt er als een fragment of artikel na de scan wordt verwijderd?
Als het fragment wordt verwijderd, mislukt het bijwerken van een artikel met het fragment en verschijnt er een bericht "Bijgewerkt mislukt" — wordt het voorstel uit de lijst verwijderd. Als een artikel na de scan wordt verwijderd, verschijnt het niet meer in de lijst met getroffen artikelen, maar het oorspronkelijke aantal gevallen (bijvoorbeeld "16 keer in 10 artikelen") weerspiegelt nog steeds de scanresultaten. Het verwijderde artikel kan niet worden geselecteerd voor update.
Wat gebeurt er als een artikel na de scan wordt bewerkt?
De preview toont: "Het lijkt erop dat het artikel is bijgewerkt sinds de laatste scan. De voorgestelde dubbele inhoud is niet langer te vinden. Alstublieft opnieuw scannen om de laatste resultaten te krijgen." Het artikel is standaard uitgeschakeld en uitgeschakeld in de preview. Als je probeert te updaten zonder eerst te previewen, geeft het resultaatbericht aan hoeveel artikelen zijn bijgewerkt en hoeveel faalden.
Verschijnen gekloonde artikelen in de scan?
Ja. De scan wordt op projectniveau uitgevoerd. Gekloonde artikelen — of ze nu binnen dezelfde werkruimte of over verschillende werkruimtes zijn aangemaakt — worden behandeld als aparte artikelen, en eventuele dubbele inhoud daarin verschijnt als een aparte vermelding in de scanresultaten.